
En el contexto del análisis financiero y la inferencia estadística, decidimos estudiar el beneficio neto trimestral de una empresa ficticia, a la que llamaremos Empresa X. Disponíamos de datos desde el año 2015 hasta 2025, con un total de 42 trimestres.
🎯 Objetivo
Estimar el beneficio neto medio poblacional a partir de datos históricos y cuantificar la incertidumbre de esa estimación, aplicando distintos enfoques estadísticos.
📋 Datos disponibles
| Trimestre | Beneficio Neto ($ millones) |
|---|---|
| 2025 Q1 | 3330 |
| 2024 Q4 | 2195 |
| 2024 Q3 | 2848 |
| 2024 Q2 | 2411 |
| 2024 Q1 | 3177 |
| 2023 Q4 | 1973 |
| 2023 Q3 | 3087 |
| 2023 Q2 | 2547 |
| 2023 Q1 | 3107 |
| 2022 Q4 | 2031 |
| 2022 Q3 | 2825 |
| 2022 Q2 | 1905 |
| 2022 Q1 | 2781 |
| 2021 Q4 | 2414 |
| 2021 Q3 | 2471 |
| 2021 Q2 | 2641 |
| 2021 Q1 | 2245 |
| 2020 Q4 | 1456 |
| 2020 Q3 | 1737 |
| 2020 Q2 | 1779 |
| 2020 Q1 | 2775 |
| 2019 Q4 | 2042 |
| 2019 Q3 | 2593 |
| 2019 Q2 | 2607 |
| 2019 Q1 | 1678 |
| 2018 Q4 | 870 |
| 2018 Q3 | 1880 |
| 2018 Q2 | 2316 |
| 2018 Q1 | 1368 |
| 2017 Q4 | -2752 |
| 2017 Q3 | 1447 |
| 2017 Q2 | 1371 |
| 2017 Q1 | 1182 |
| 2016 Q4 | 550 |
| 2016 Q3 | 1046 |
| 2016 Q2 | 3448 |
| 2016 Q1 | 1483 |
| 2015 Q4 | 1237 |
| 2015 Q3 | 1449 |
| 2015 Q2 | 3108 |
| 2015 Q1 | 1557 |
🧪 Paso 1: Estadísticos de la muestra
Con los 42 trimestres, calculamos:

- Media muestral (𝑥̄): 2005.24 millones
- Desviación estándar muestral (s): 723.18 millones
- Error estándar de la media (SE): 111.99 millones
- La media nos da una idea del beneficio neto promedio, pero hay una dispersión considerable (desviación estándar) en los datos.
📐 Paso 2: Intervalo de confianza con t de Student
Al no conocer la varianza poblacional y trabajar con una muestra de tamaño moderado, usamos la distribución t de Student.
Para un nivel de confianza del 95% y 41 grados de libertad (n-1), el valor crítico t es aproximadamente 2.0195.
El intervalo de confianza es:

Esto indica que, con un 95% de confianza, el beneficio neto medio poblacional está en este rango.
Sin embargo, sabemos que:
✅ No es lo mismo calcular la media muestral que la distribución muestral de la media.
🎯 Diferencia clave
1. Media muestral
- Es un único valor.
- Se calcula directamente a partir de tu muestra:
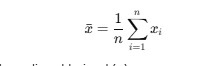
- Es un estimador puntual de la media poblacional (μ\muμ).
2. Distribución muestral de la media
- Es una distribución completa: describe todas las posibles medias muestrales que podrías obtener si repitieras el muestreo muchas veces.
- Tiene:
- Media: igual a μ\mu (media poblacional)
- Desviación estándar: → /
 esto es el error estándar
esto es el error estándar
- No la calculas directamente como un número, sino que usas su forma teórica (normal o t de Student) para hacer inferencias, como intervalos de confianza o pruebas de hipótesis.
🔁 Entonces, cuando dices:
“¿Usamos la media o la distribución muestral para el intervalo?”
La respuesta es:
👉 Usamos la media muestral como centro del intervalo, y
👉 la distribución muestral (específicamente su error estándar y forma t) para construir el margen de error.
🔁 Paso 3: Intervalo de confianza Bootstrap
Simulamos 10,000 medias muestrales por remuestreo con reemplazo (bootstrap) de tamaño n=42.
/import numpy as np
Datos del beneficio neto trimestral
data = np.array([
3330, 2195, 2848, 2411, 3177, 1973, 3087, 2547, 3107, 2031, 2825, 1905, 2781,
2414, 2471, 2641, 2245, 1456, 1737, 1779, 2775, 2042, 2593, 2607, 1678, 870,
1880, 2316, 1368, -2752, 1447, 1371, 1182, 550, 1046, 3448, 1483, 1237, 1449,
3108, 1557
])
Configuración del bootstrap
np.random.seed(42)
n_iterations = 10000
sample_size = len(data)
Generar medias por remuestreo con reemplazo
bootstrap_means = np.array([
np.mean(np.random.choice(data, size=sample_size, replace=True))
for _ in range(n_iterations)
])
Calcular intervalo de confianza del 95%
ci_lower = np.percentile(bootstrap_means, 2.5)
ci_upper = np.percentile(bootstrap_means, 97.5)
print(f»Intervalo de confianza bootstrap (95%): [{ci_lower:.2f}, {ci_upper:.2f}]»)
El intervalo de confianza al 95% fue:
- Resultado empírico al 95%:
[1653.73, 2295.23]
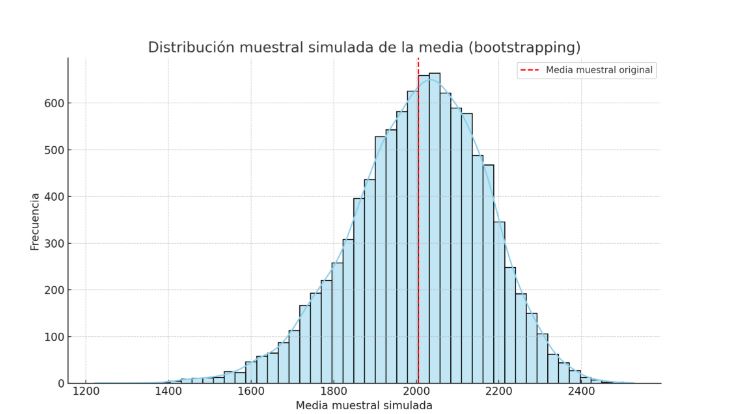
📊 Comparación de métodos
| Método | Intervalo de Confianza (95%) |
|---|---|
| t de Student | [1673.37, 2337.11] |
| Bootstrap | [1653.73, 2295.23] |
Ambos métodos arrojaron resultados consistentes. La t de Student es más conservadora, mientras que el bootstrap no requiere asumir normalidad.
🧠 ¿Qué aprendimos?
- La media muestral es solo una estimación puntual.
- La distribución muestral de la media nos da una idea de cómo varía esa media si repitiésemos el estudio muchas veces.
- Métodos como bootstrap nos permiten obtener inferencias sin suposiciones fuertes sobre la distribución subyacente.
- El tamaño de la muestra afecta directamente la precisión del intervalo.
🧩 Reflexión final
Este ejercicio muestra cómo combinar estadística clásica y computacional para tomar decisiones informadas. En análisis financiero o cualquier campo con incertidumbre, es fundamental no solo estimar valores, sino entender la variabilidad de nuestras estimaciones.
1. Inestabilidad en los resultados:
Pros:
Refleja con mayor precisión la volatilidad real del negocio.
Transparencia completa: se muestra el impacto real de eventos y cambios en el mercado.
Ayuda a detectar problemas a tiempo para tomar acciones correctivas.
Contras:
Puede generar incertidumbre y desconfianza en inversores y mercados.
Dificulta la planificación y toma de decisiones si los resultados son muy variables.
Puede afectar la valoración y el costo de capital por mayor percepción de riesgo.
2. Uso de provisiones, ajustes en balance, etc. (“suavizar” resultados):
Pros:
Reduce la volatilidad aparente, mostrando resultados más estables y predecibles.
Facilita la comunicación y la confianza en el mercado.
Permite una mejor planificación financiera y operativa.
Contras:
Puede ocultar problemas reales o riesgos subyacentes si se usa en exceso.
Riesgo de manipulación contable o “window dressing” que afecta la credibilidad.
Menor transparencia para usuarios que buscan entender la verdadera salud financiera.
Lo ideal es encontrar un equilibrio entre transparencia y estabilidad:
Usar provisiones y ajustes de forma prudente y justificada, con criterios claros y consistentes.
Mantener una comunicación abierta con los stakeholders sobre cómo se gestionan estos ajustes.
Incorporar métricas complementarias (como cash flow operativo, indicadores de riesgo) para dar una visión más completa.
Evitar ocultar problemas reales que pueden afectar la sostenibilidad a largo plazo.
Este ejercicio demuestra la utilidad de combinar métodos estadísticos clásicos con técnicas computacionales para evaluar el beneficio neto de una empresa. Comprender la variabilidad e incertidumbre en estos datos es clave para planificar y gestionar riesgos.
📝 Consideraciones sobre el beneficio neto y otros indicadores financieros
Es importante recordar que el beneficio neto es solo uno de los múltiples indicadores financieros disponibles para evaluar la salud y desempeño de una empresa. Otros indicadores, como el free cash flow (flujo de caja libre), pueden proporcionar información complementaria y en ocasiones diferente.
El beneficio neto se basa en principios contables y puede incluir partidas no monetarias (como depreciaciones o provisiones) o efectos fiscales, mientras que el free cash flow refleja el dinero realmente generado y disponible para la empresa después de inversiones en capital y operaciones. Por lo tanto, no necesariamente coinciden en magnitud ni en tendencia.
Este tipo de análisis estadístico —estimación puntual, intervalos de confianza, y evaluación de incertidumbre— es igualmente aplicable a series de tiempo financieras distintas al beneficio neto, como ingresos, EBITDA, o free cash flow, permitiendo así una visión más completa y robusta para la toma de decisiones.
Lo ideal es encontrar un equilibrio entre transparencia y estabilidad en la presentación de resultados financieros:
- Utilizar provisiones y ajustes contables de forma prudente y justificada, con criterios claros y consistentes.
- Mantener una comunicación abierta y honesta con los stakeholders sobre cómo y por qué se aplican esos ajustes.
- Complementar la información financiera con métricas adicionales como flujos de caja operativos o indicadores de riesgo.
- Evitar prácticas que oculten problemas reales y pongan en riesgo la sostenibilidad a largo plazo.
Adicionalmente, es muy recomendable incorporar métodos estadísticos para evaluar y monitorear los resultados. Técnicas como análisis de series temporales, intervalos de confianza, pruebas de hipótesis o bootstrap pueden ayudar a:
- Cuantificar la incertidumbre y variabilidad en los resultados.
- Detectar desviaciones significativas o tendencias preocupantes.
- Tomar decisiones basadas en evidencia, minimizando el ruido y la volatilidad aleatoria.
Este enfoque estadístico aporta rigor y objetividad, fortaleciendo la confianza en la información financiera y facilitando una gestión más efectiva.
¿Qué es un proceso robusto y estable en calidad?
- Estabilidad del proceso
- El proceso opera con variación mínima a lo largo del tiempo, sin cambios inesperados o “saltos” en la calidad.
- Se mantiene dentro de los límites de control estadístico, es decir, la variabilidad está bajo control y predecible.
- Capacidad del proceso
- El proceso es capaz de producir consistentemente productos o resultados que cumplen con las especificaciones o estándares de calidad.
- Se mide con índices como Cp, Cpk, que indican si la variabilidad y el centrado del proceso están alineados con las tolerancias definidas.
- Robustez
- El proceso es resistente a variaciones en las condiciones (materia prima, ambiente, operarios, etc.) sin que se degrade la calidad.
- Se diseñan controles y tolerancias que minimizan el impacto de factores externos o internos.
- Reproducibilidad y repetibilidad
- Se pueden obtener los mismos resultados bajo las mismas condiciones, incluso replicando el proceso en distintos momentos o por distintos operadores.
- Capacidad para detectar y corregir desviaciones
- El sistema incluye monitoreo continuo y mecanismos para detectar rápidamente cualquier desviación del proceso y corregirla antes de que impacte al producto final.
¿Cómo se evalúa en la práctica?
- Análisis estadístico:
Control estadístico de procesos (SPC) con gráficos de control, análisis de capacidad. - Auditorías y revisiones:
Evaluación periódica para asegurar que el proceso sigue cumpliendo estándares. - Pruebas de estrés o variación controlada:
Para medir cómo responde el proceso a cambios intencionales en variables críticas. - Documentación y estandarización:
Procedimientos claros que minimizan la variabilidad humana y facilitan la consistencia.
📝 Conclusión adicional sobre el dato negativo
Observamos que en 2017 Q4 el beneficio neto fue negativo (-2752 millones), mientras que en otros trimestres los valores son positivos. Este dato negativo puede corresponder a una inversión inicial significativa, un desembolso importante que afectó ese trimestre. Los beneficios positivos en los trimestres y años siguientes representarían los flujos de caja que permiten recuperar dicha inversión y generar valor. Por tanto, este análisis no solo evalúa la rentabilidad promedio, sino también el ciclo financiero típico de una empresa que primero invierte y luego recupera su capital.
#DataScience #Estadística #AnálisisFinanciero #Bootstrap #InferenciaEstadística #IntervalosDeConfianza #LinkedInInsights #CienciaDeDatos





Deja un comentario