🗂 Introducción: Presentación del Dataset y Desafío
Pronosticar ventas es crucial para cualquier empresa: permite gestionar inventarios, planificar recursos y tomar decisiones estratégicas. En este proyecto trabajamos con el dataset “Store Sales Forecasting” de Kaggle, que refleja situaciones reales del comercio retail en Ecuador.
Características principales del dataset:
🗓 Fecha de venta
🏪 ID de tienda y ID de producto
💰 Precio unitario y cantidad vendida
🎯 Promoción activa
🏷 Categoría de producto y ubicación de la tienda
📅 Fechas de inicio y fin de promoción
Ventajas del dataset:
Cobertura temporal para analizar tendencias y estacionalidad
Variedad de variables para modelos predictivos robustos
Contexto comercial real con promociones y cambios de precio
Desafíos:
Valores faltantes que requieren imputación
Variabilidad por promociones que añade ruido a las series
Entorno de trabajo: Usamos Google Colab por su facilidad para compartir, ejecutar notebooks y acceso a GPUs/TPUs.
Exploramos la estructura del dataset: 3.000.888filas, 7 columnas. Incluye variables de ventas, tiendas, productos y promociones.
Estadísticas descriptivas:
Estadística
id
date
store_nbr
sales
onpromotion
sales_log
count
3,000,888
3,000,888
3,000,888
3,000,888
3,000,888
3,000,888
mean
1,500,443.50
2015-04-24 08:27:04
27.50
357.78
2.60
2.93
min
0.00
2013-01-01 00:00:00
1.00
0.00
0.00
0.00
25%
750,221.75
2014-02-26 18:00:00
14.00
0.00
0.00
0.00
50%
1,500,443.50
2015-04-24 12:00:00
27.50
11.00
0.00
2.48
75%
2,250,665.25
2016-06-19 06:00:00
41.00
195.85
0.00
5.28
max
3,000,887.00
2017-08-15 00:00:00
54.00
124,717.00
741.00
11.73
std
866,281.89
NaN
15.59
1,102.00
12.22
2.70
Hallazgos clave:
Valores nulos en dcoilwtico → plan de imputación
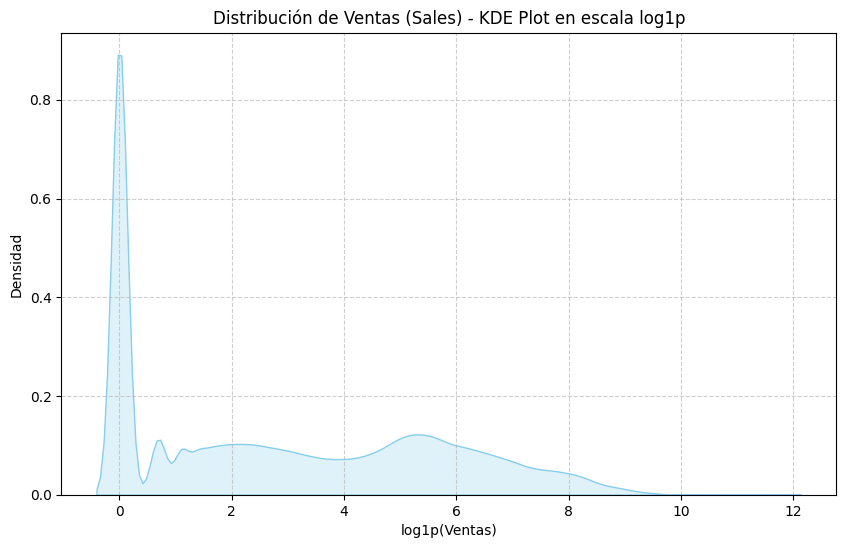
Fuerte asimetría en ventas → aplicamos logventas
📊 Visualizando la distribución de sales para ventas totales (KDE Plots)...
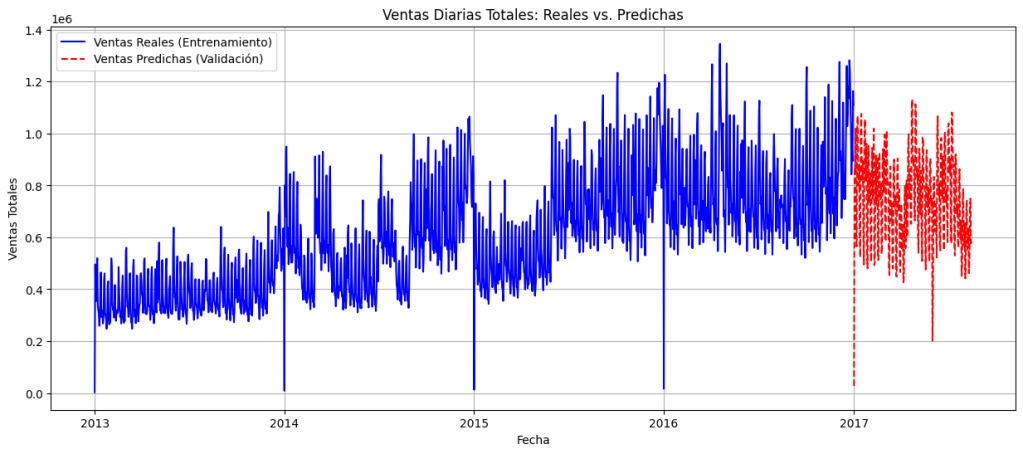
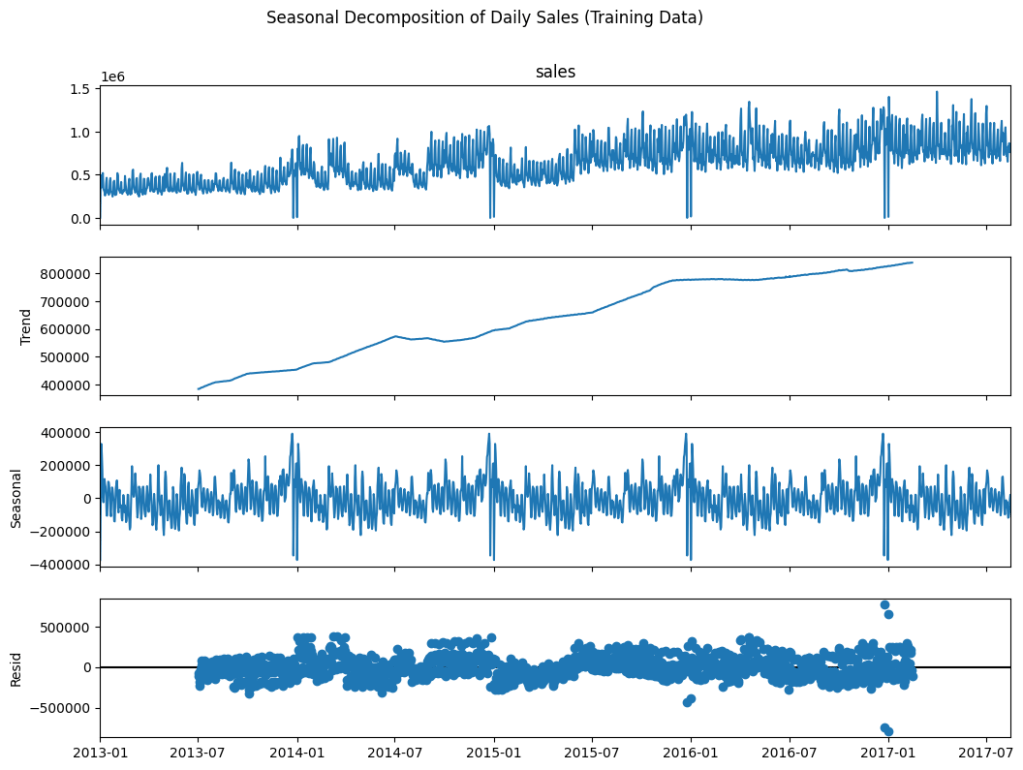
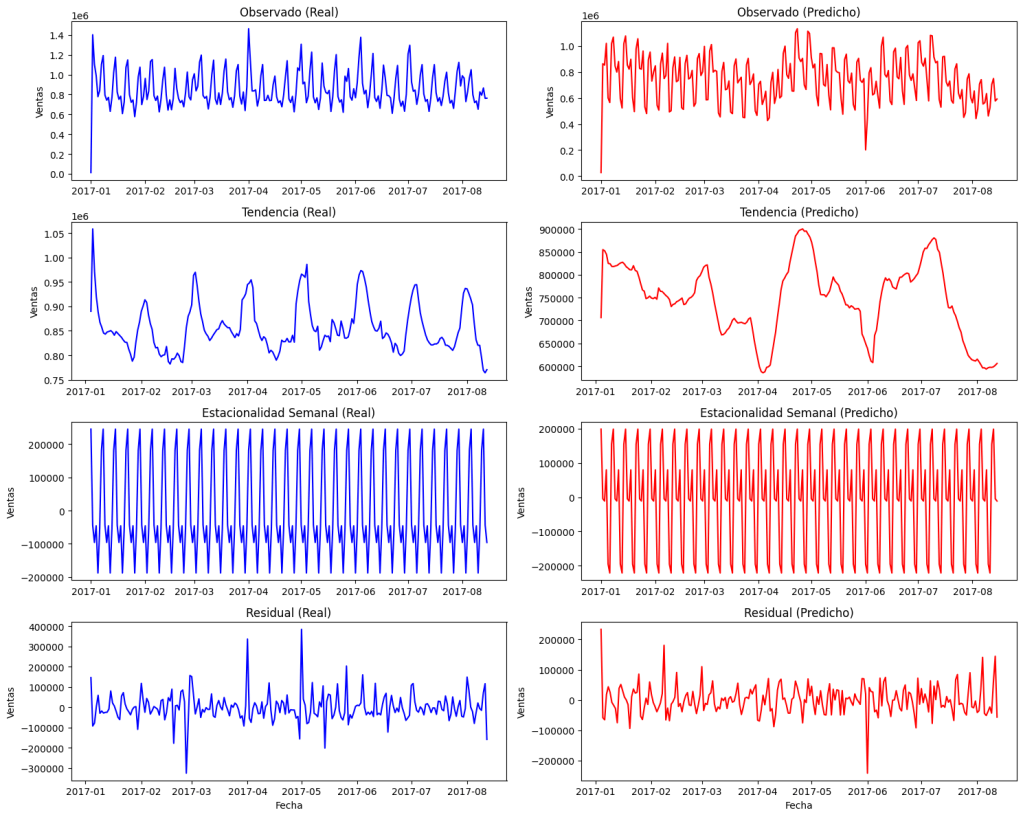
📅 Serie Temporal: Tendencia y Estacionalidad
Analizamos la serie temporal de ventas para identificar patrones:
Tendencias (crecientes o decrecientes)
Estacionalidad semanal y anual
📊Performing seasonal decomposition on daily sales from the training data…
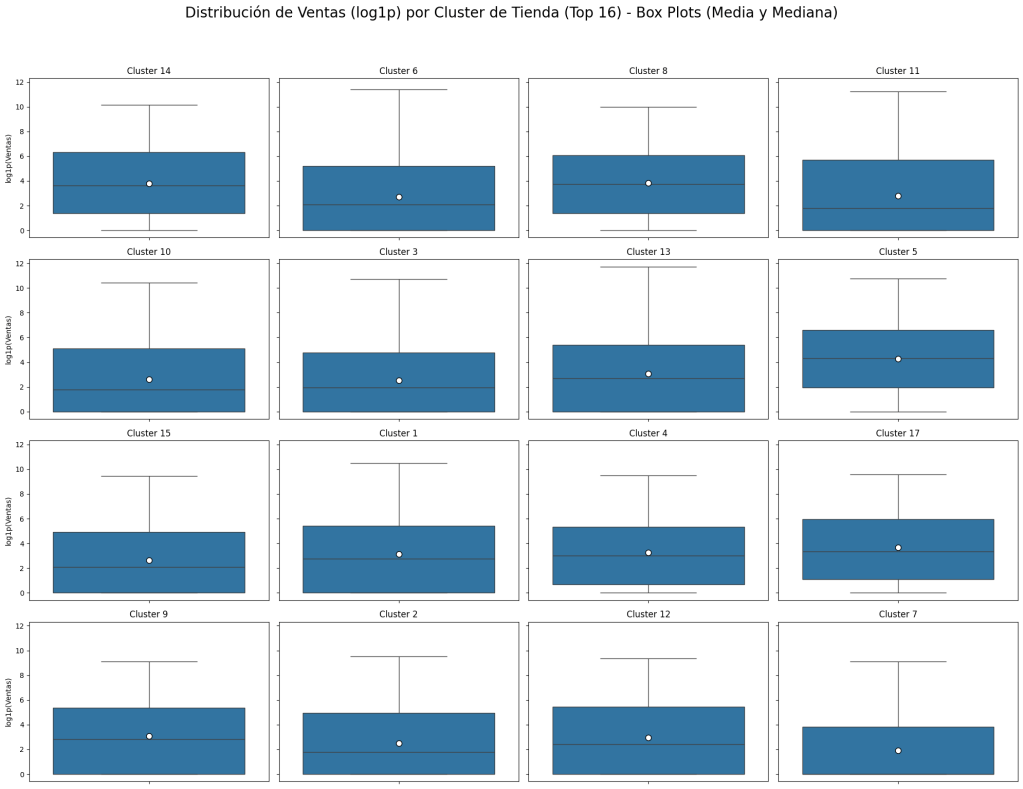
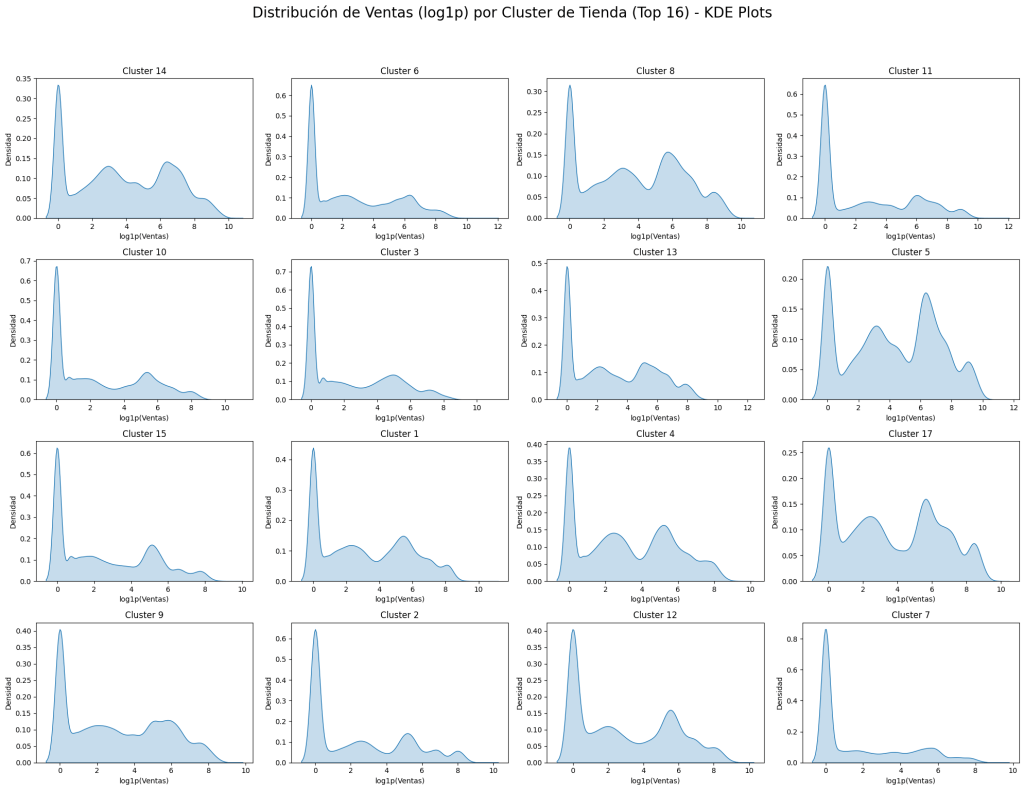
🏷 Ventas por Categoría y Clusters
Exploramos clusters de tiendas y categorías de productos:
Boxplots y KDEs muestran distribución de sales_log por cluster
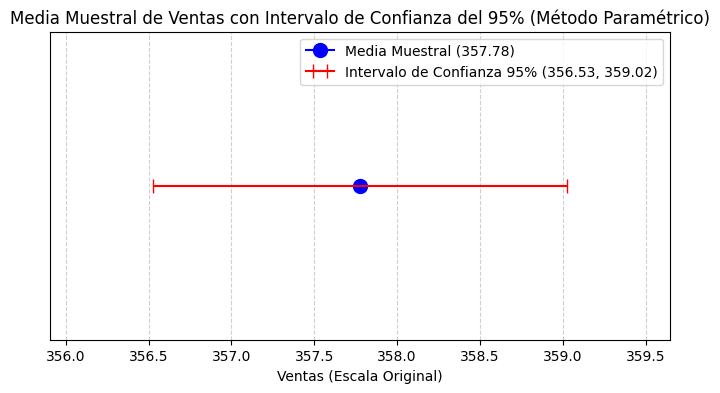
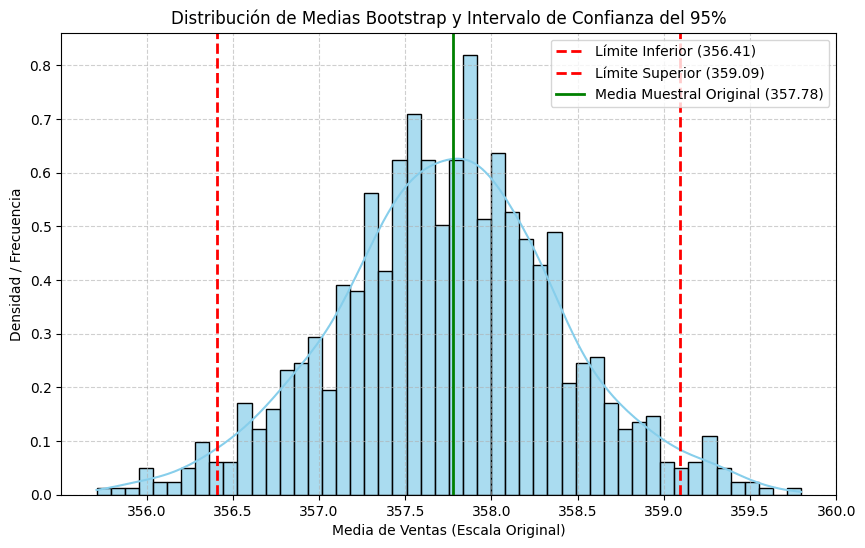
Intervalos de confianza (CI) calculados con t-test y bootstrapping
📊 Merging train_df with stores_df to get cluster information…
Visualizando la distribución de sales_log para los 16 clusters con mayores ventas totales (Box Plots con Media y Mediana)…
Generando gráfico de la Media Muestral con Intervalo de Confianza (Método Paramétrico)...
Generando gráfico de distribución de medias Bootstrap con el intervalo de confianza...
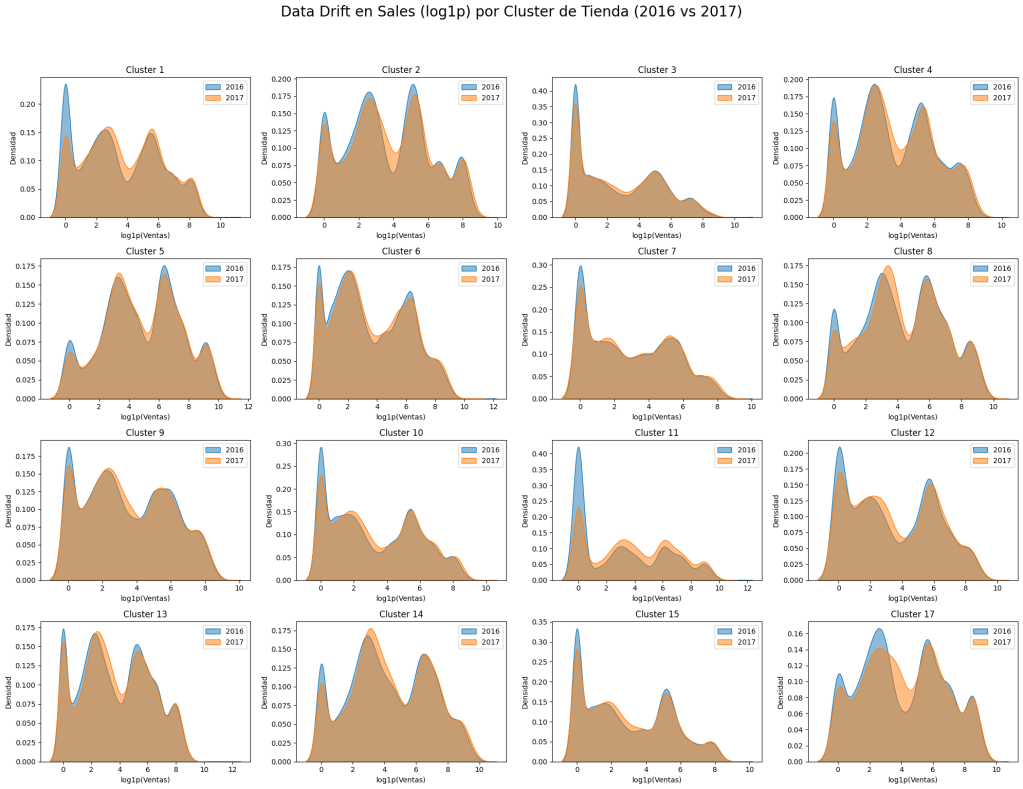
Data Drift: Cambios en la Distribución
El data drift ocurre cuando los datos cambian con el tiempo, afectando el modelo:
Comparación de sales_log y onpromotion entre 2016 y 2017
Diferencias significativas → requieren estrategias para manejar drift
📊 Gráficos sugeridos:
Merging train_df with stores_df to get cluster information...
Visualizando Data Drift en sales_log entre 2016 y 2017 para 16 clusters...
⚙ Ingeniería de Características
Creamos nuevas variables:
⏱ Temporales: día del año, semana, día de la semana
🔗 Fusionadas: información de tiendas, petróleo, transacciones, festivos
Dividimos los datos cronológicamente en entrenamiento y validación.
🔹 Tip de blog: Incluir tabla resumen de nuevas features.
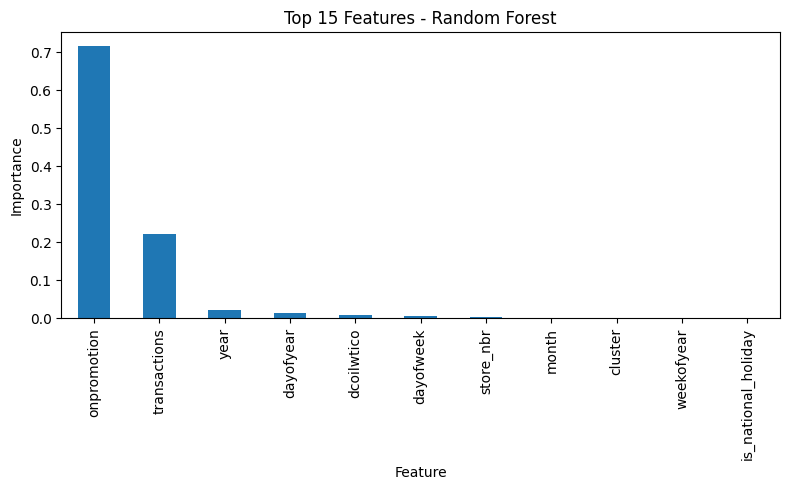
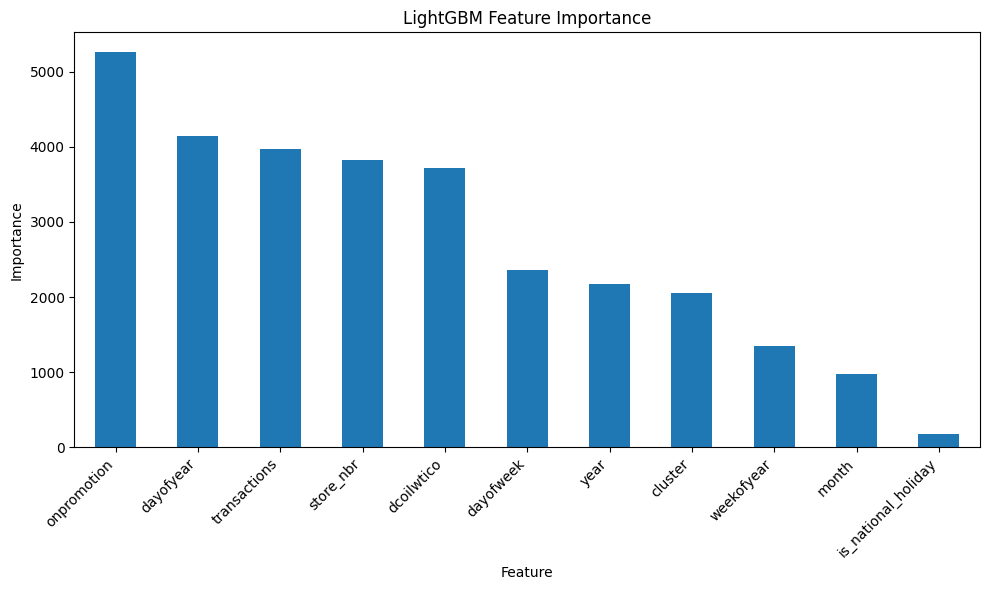
🌳 Modelos: LightGBM y Random Forest
Entrenamos modelos de árboles ensemble sobre sales_log:
LightGBM: rápido, soporta early stopping y registros de entrenamiento
Random Forest: baseline robusto
📊
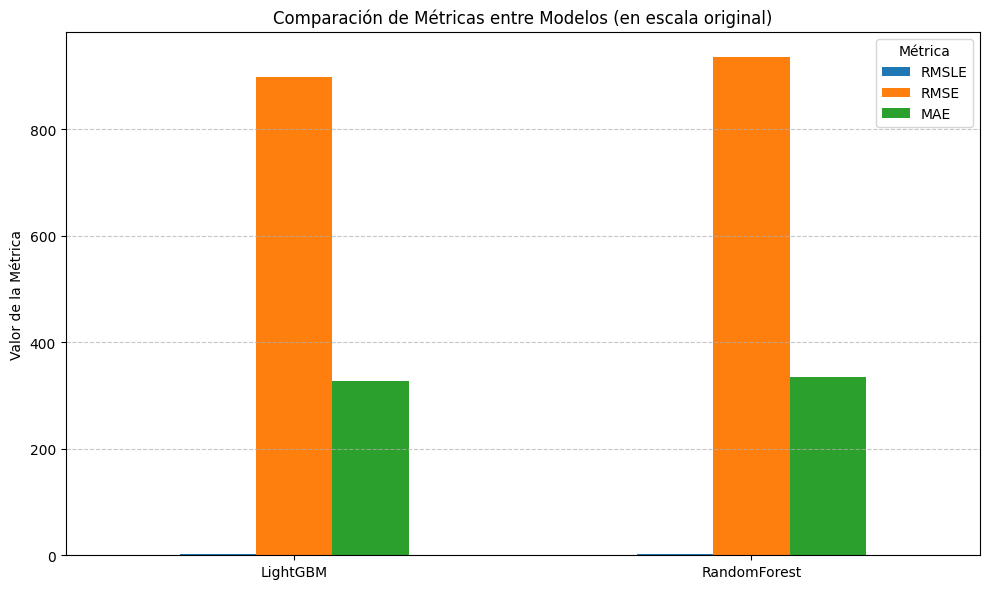
📏 Evaluación del Modelo
Métricas clave:
RMSLE: error relativo logarítmico
RMSE y MAE: errores absolutos y cuadráticos
RMSLE
RMSE
MAE
LightGBM
1.585825
897.928511
327.798349
RandomForest
1.623474
936.488931
334.167101
📈 Evolución del entrenamiento LightGBM:
⚠️ El modelo LightGBM no contiene 'evals_result_' o no es una instancia de LGBMRegressor. Asegúrate de usar eval_set en el fit().
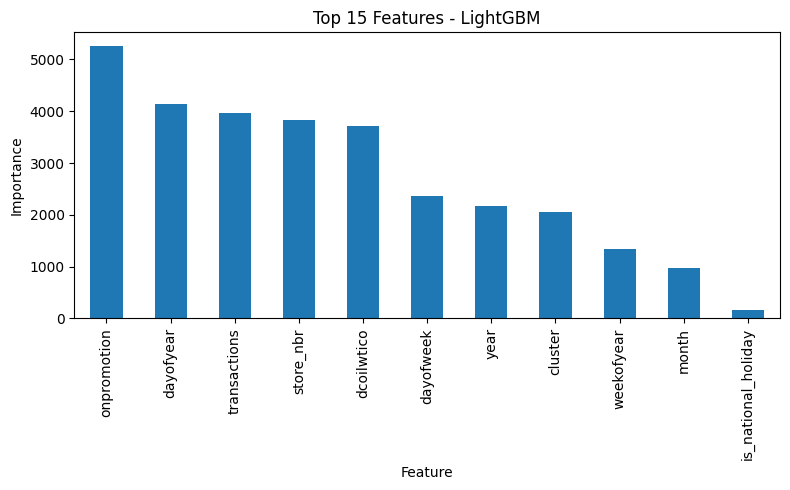
🌳 Importancia de Variables:
🔍 Interpretación del Modelo
Feature importance de LightGBM
PDPs para visualizar relación entre características y predicción
⚠ Nota: Para interpretaciones individuales o interacciones, usar valores SHAP.
🏁 Conclusiones y Próximos Pasos
Hallazgos:
log1p estabilizó la distribución de ventas
LightGBM superó a Random Forest
Data drift y clusters requieren atención futura
Próximos pasos:
Más ingeniería de características
Ajuste de hiperparámetros
Incorporar SHAP para interpretabilidad
Estrategias avanzadas para data drift
💡 Trabajar con este proyecto de pronóstico de ventas me permitió comprender de manera práctica cómo se comportan las series temporales en el comercio minorista y cómo factores como promociones, variaciones de precios y cambios estacionales influyen en las ventas.
Además, pude aplicar herramientas de análisis exploratorio, modelado con LightGBM y Random Forest, y técnicas de incertidumbre y data drift, reforzando la importancia de entender los datos antes de construir modelos predictivos.
En el mundo real, estos conocimientos son directamente aplicables a la gestión de inventarios, planificación de recursos y estrategias comerciales.
Cada decisión basada en datos tiene el potencial de optimizar costos, mejorar la experiencia del cliente y aumentar la rentabilidad de una empresa.
Bienvenido/a a El taller de datos, mi acogedor rincón en internet dedicado a todo lo relacionado con mi aprendizaje de este mundo analítico. Aquí te invito a acompañarme en un viaje de creatividad, artesanía y todo hecho a mano con un toque de amor. ¡Vamos a ponernos creativos!







Deja un comentario