
En machine learning, la calidad y estructura de los datos influyen directamente en el rendimiento del modelo. Dos aspectos fundamentales a considerar son el desbalanceo de clases y la forma en que dividimos los datos en conjuntos de entrenamiento y prueba.
¿Qué es el Desbalanceo de Clases?
El desbalanceo ocurre cuando una o varias clases tienen muchas más muestras que otras. Por ejemplo, en un conjunto de datos para detectar fraudes, los casos fraudulentos suelen ser una minoría.
¿Por qué es un problema?
- Modelos sesgados: Aprenden más sobre la clase mayoritaria y menos sobre la minoritaria.
- Métricas engañosas: Una alta precisión puede ocultar que el modelo no detecta bien las clases minoritarias.
¿Cuándo decimos que un dataset está balanceado?
- Cuando la cantidad de muestras por clase es similar o con diferencias pequeñas.
- Algunas métricas útiles para medir balance son:
- Proporción mínima: Que ninguna clase tenga menos del 80-90% de muestras respecto a la más frecuente.
- Coeficiente de variación: Desviación estándar sobre la media de las cantidades por clase, idealmente bajo 10%.
Métodos para dividir datos: Train y Test
Separar correctamente los datos es vital para evaluar el modelo de forma justa.
1. Split Aleatorio Simple
Divide al azar, por ejemplo, 80% para entrenamiento y 20% para prueba.
- Fácil de implementar.
- Riesgo: puede no mantener la proporción de clases.
2. Split Estratificado
Divide respetando la proporción de clases en ambos conjuntos.
- Ideal para datasets con clases desbalanceadas.
- Garantiza que todas las clases estén bien representadas.
3. Particiones Fijas
Algunos datasets vienen con divisiones oficiales (como MNIST).
- Útil para comparar resultados con benchmarks estándar.
- Un conjunto de datos balanceado es fundamental para que los modelos de machine learning aprendan a distinguir correctamente todas las clases, incluyendo aquellas que están menos representadas.
Impacto del desbalanceo en el aprendizaje
Cuando una clase está poco representada (clase minoritaria) y otra tiene muchas muestras (clase mayoritaria), el modelo tiende a:
- Aprender sesgadamente hacia la clase mayoritaria: Dado que ve muchos ejemplos de una clase, prioriza acertar en ella para minimizar el error global.
- Ignorar o predecir mal la clase minoritaria: Como hay pocos ejemplos, el modelo no «aprende» sus características con suficiente profundidad y tiende a confundirla o ignorarla.
- Resulta en un modelo con alta precisión aparente, pero pobre rendimiento en las clases minoritarias, algo muy peligroso en aplicaciones críticas (fraude, diagnóstico médico, detección de spam).
Importancia de la partición balanceada
Incluso si el dataset original es balanceado, una mala partición puede romper ese balance:
- Si en el conjunto de entrenamiento no hay suficientes ejemplos de la clase minoritaria, el modelo no tendrá oportunidad de aprender sus patrones.
- Si el conjunto de prueba está desbalanceado, la evaluación del modelo será poco representativa y puede dar métricas engañosas.
Por eso, el uso de particiones estratificadas que mantengan la proporción de clases en ambos conjuntos es una práctica esencial.
¿En qué modelos es más crítico?
- Modelos simples o poco flexibles: Como regresión logística, máquinas de soporte vectorial (SVM), árboles de decisión sin poda, que dependen mucho de la cantidad de ejemplos para aprender patrones robustos.
- Redes neuronales: Aunque son potentes, si las clases minoritarias tienen muy pocos ejemplos, la red puede sobreajustar a la clase mayoritaria o no generalizar bien para las minoritarias.
- Modelos basados en frecuencia o conteo: Como Naive Bayes, donde la estimación de probabilidades depende directamente del conteo de ejemplos.
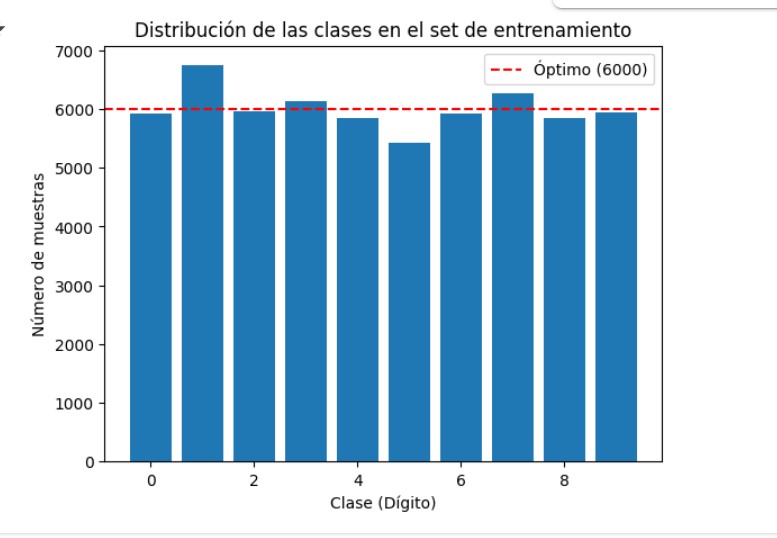
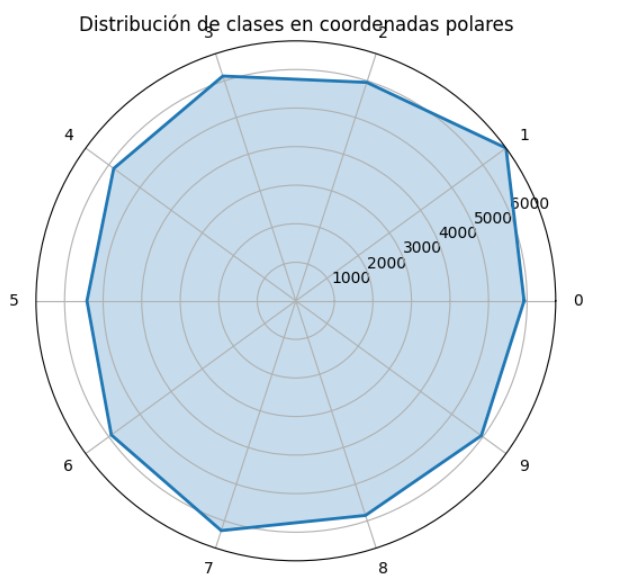
Evaluar el balanceo de clases es un paso crucial en cualquier proyecto de clasificación. Existen varias métricas que nos permiten cuantificar este equilibrio, como el coeficiente de variación, el índice de Gini, el ratio entre la clase más y menos representada, o el análisis del número de muestras por clase en relación con la media. Todas ellas ofrecen una visión más precisa que simplemente «verlo a ojo», y ayudan a detectar desviaciones que podrían afectar el rendimiento del modelo.
En el caso del dataset MNIST, he calculado el coeficiente de variación:
import numpy as np
values = np.array(list(class_counts.values()))
cv = np.std(values) / np.mean(values)
print(f"Coeficiente de variación: {cv:.3f}")
Mide la dispersión relativa respecto a la media: CV=σ/μ
- σ= desviación estándar del número de muestras por clase
- μ = media del número de muestras por clase
Interpretación:
- CV cercano a 0 indica clases muy balanceadas.
- CV > 0.1 o 0.2 indica desbalance considerable.
En nuestro caso, Coeficiente de variación: 0.054
Esto confirma que las diferencias en el número de muestras entre las clases son pequeñas y probablemente no afectarán negativamente al entrenamiento de tu modelo.
En caso de diferencias significativas, podríamos probar o aplicar técnicas correctivas como :
Data Augmentation
Resampling (undersampling/oversampling)
Class weighting en el modelo
Es fundamental para asegurar que el modelo aprenda a distinguir correctamente todas las clases, sin sesgarse hacia las más frecuentes. Este análisis debe considerarse tanto en la etapa de exploración inicial como al realizar la partición entre entrenamiento y prueba, para construir modelos más justos, robustos y eficaces.





Deja un comentario